

How to use foundation models and trusted governance to manage AI workflow risk
IBM Big Data Hub
OCTOBER 16, 2023
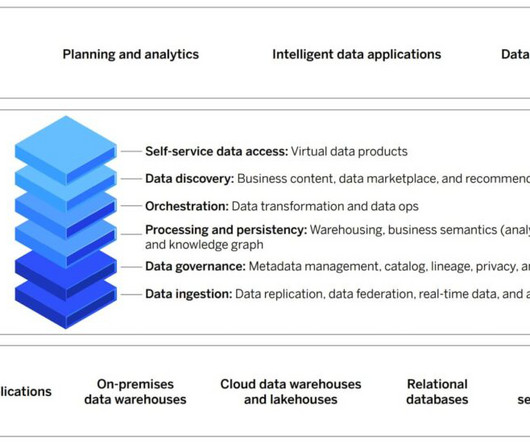
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. Foundation models: The power of curated datasets Foundation models , also known as “transformers,” are modern, large-scale AI models trained on large amounts of raw, unlabeled data.










































Let's personalize your content