

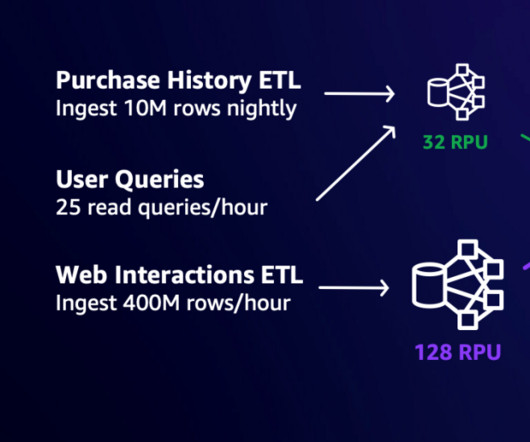
Improve your ETL performance using multiple Redshift warehouses for writes
AWS Big Data
FEBRUARY 19, 2024
Amazon Redshift is a fast, petabyte-scale, cloud data warehouse that tens of thousands of customers rely on to power their analytics workloads. Thousands of customers use Amazon Redshift read data sharing to enable instant, granular, and fast data access across Redshift provisioned clusters and serverless workgroups.













































Let's personalize your content