

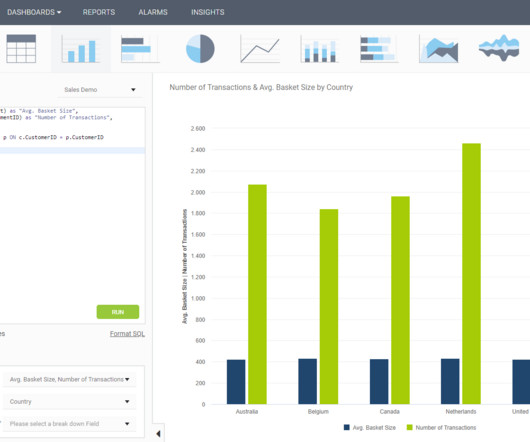
Create Modern SQL Dashboards With Professional Tools & Software
datapine
APRIL 8, 2020
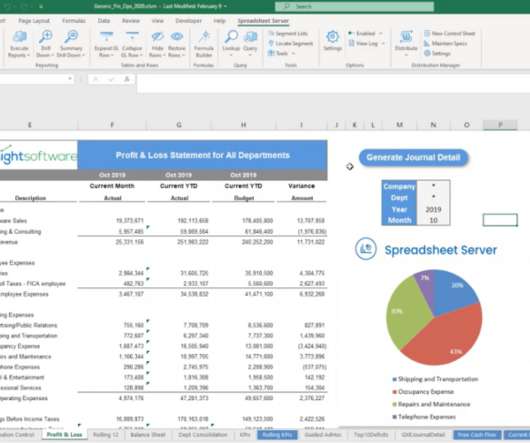
Companies need to collect, store, monitor, and analyze massive volumes of data in order to manage business performance and successfully deliver profitable results. There is still lots of relational database management included when it comes to online data analysis and different possibilities to perform the same.




































Let's personalize your content