
Speed up queries with the cost-based optimizer in Amazon Athena
AWS Big Data
NOVEMBER 17, 2023
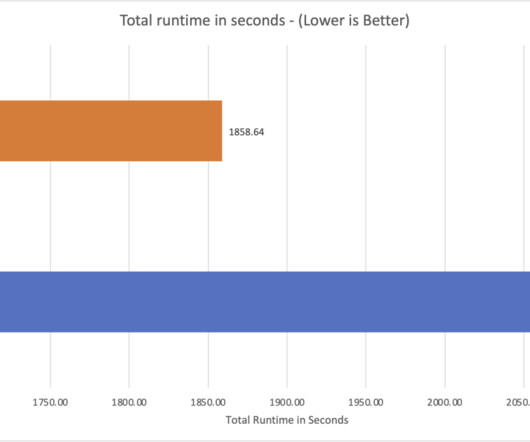
Amazon Athena is a serverless, interactive analytics service built on open source frameworks, supporting open table file formats. Starting today, the Athena SQL engine uses a cost-based optimizer (CBO), a new feature that uses table and column statistics stored in the AWS Glue Data Catalog as part of the table’s metadata.

















































Let's personalize your content