
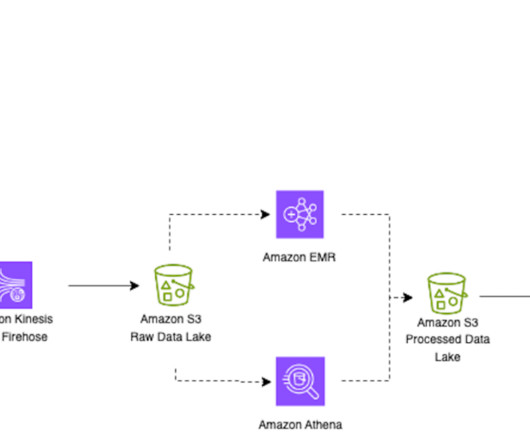
Apache Iceberg optimization: Solving the small files problem in Amazon EMR
AWS Big Data
OCTOBER 3, 2023
Systems of this nature generate a huge number of small objects and need attention to compact them to a more optimal size for faster reading, such as 128 MB, 256 MB, or 512 MB. For more information on streaming applications on AWS, refer to Real-time Data Streaming and Analytics. with Spark 3.3.2, and JupyterEnterpriseGateway 2.6.0.








































Let's personalize your content