

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
AWS Big Data
OCTOBER 1, 2024
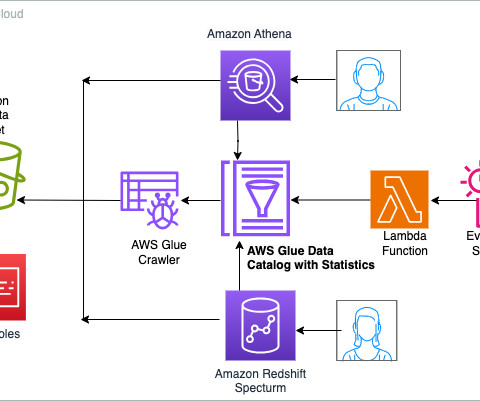
Amazon Redshift enables you to efficiently query and retrieve structured and semi-structured data from open format files in Amazon S3 data lake without having to load the data into Amazon Redshift tables. Amazon Redshift extends SQL capabilities to your data lake, enabling you to run analytical queries.









































Let's personalize your content