

How Ruparupa gained updated insights with an Amazon S3 data lake, AWS Glue, Apache Hudi, and Amazon QuickSight
AWS Big Data
FEBRUARY 22, 2023
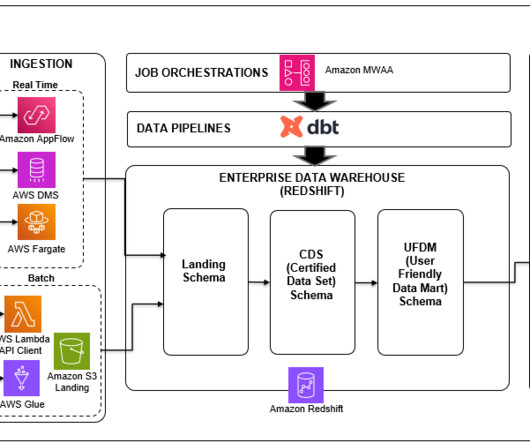
In this post, we show how Ruparupa implemented an incrementally updated data lake to get insights into their business using Amazon Simple Storage Service (Amazon S3), AWS Glue , Apache Hudi , and Amazon QuickSight. An AWS Glue ETL job, using the Apache Hudi connector, updates the S3 data lake hourly with incremental data.









































Let's personalize your content