

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
AWS Big Data
NOVEMBER 10, 2023
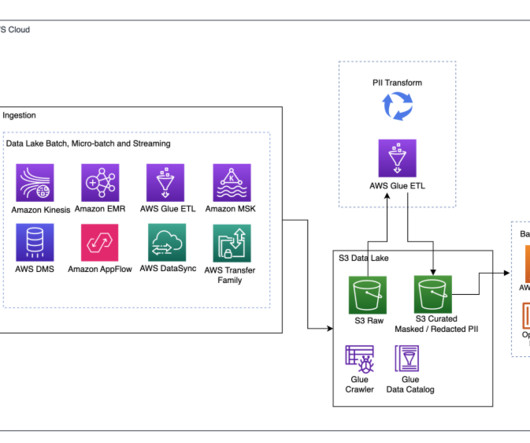
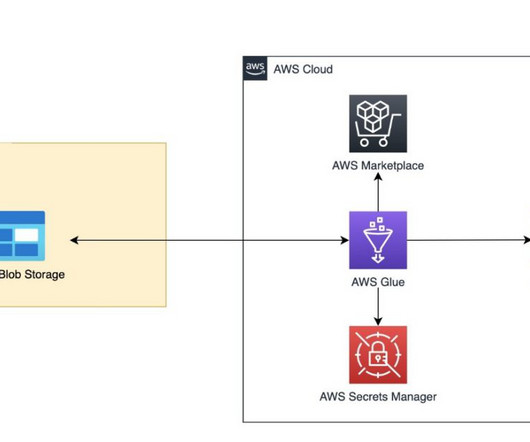
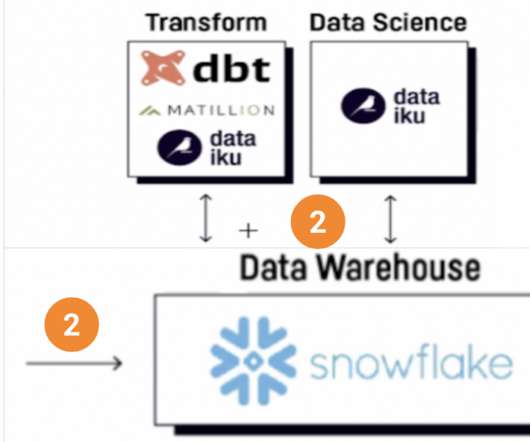
Your applications can seamlessly read from and write to your Amazon Redshift data warehouse while maintaining optimal performance and transactional consistency. Additionally, you’ll benefit from performance improvements through pushdown optimizations, further enhancing the efficiency of your operations. options(**read_config).option("query",

































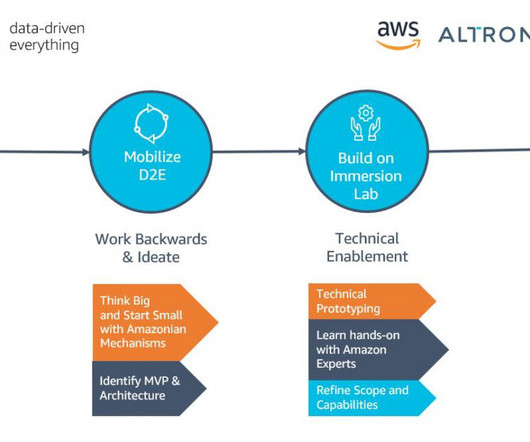




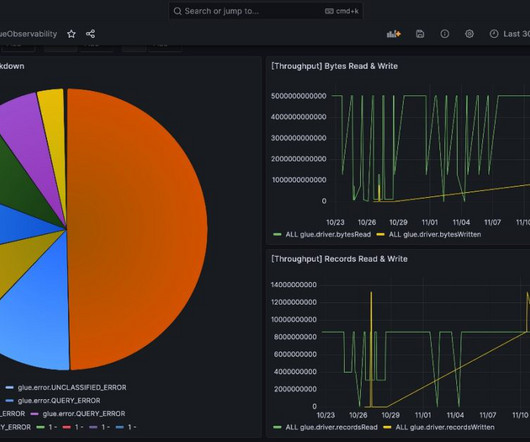








Let's personalize your content