
Empowering data-driven excellence: How the Bluestone Data Platform embraced data mesh for success
AWS Big Data
FEBRUARY 27, 2024
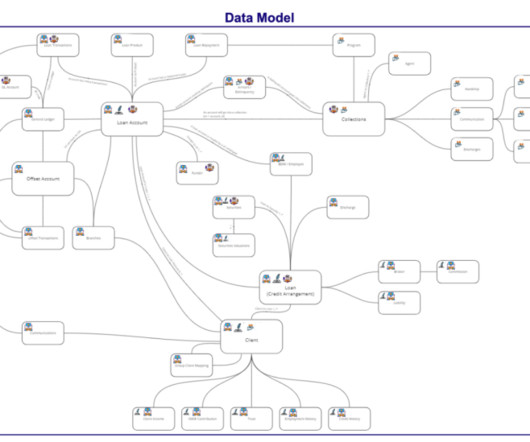
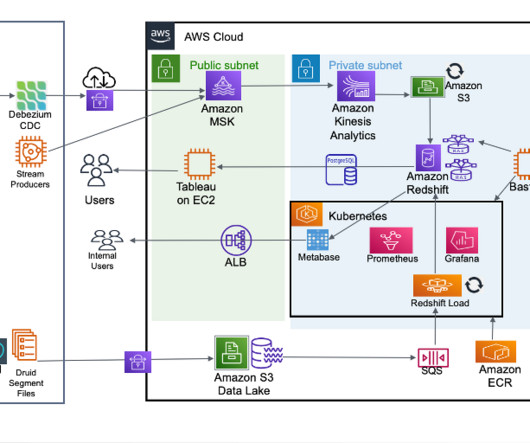
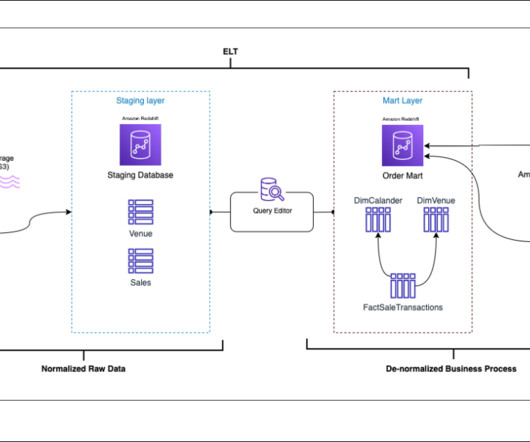
In the ever-evolving world of finance and lending, the need for real-time, reliable, and centralized data has become paramount. Bluestone , a leading financial institution, embarked on a transformative journey to modernize its data infrastructure and transition to a data-driven organization.











































Let's personalize your content