

Generate Reports Using Pandas Profiling, Deploy Using Streamlit
Analytics Vidhya
JUNE 25, 2021
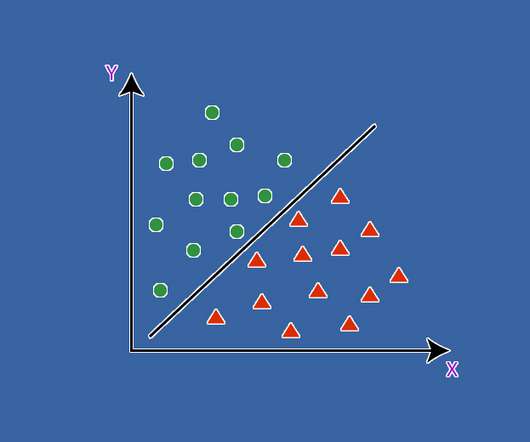
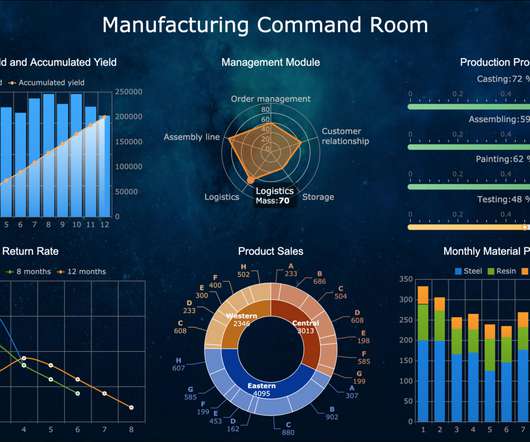
ArticleVideo Book This article was published as a part of the Data Science Blogathon Introduction Pandas library offers a wide range of functions. The post Generate Reports Using Pandas Profiling, Deploy Using Streamlit appeared first on Analytics Vidhya.































Let's personalize your content