

Orchestrate an end-to-end ETL pipeline using Amazon S3, AWS Glue, and Amazon Redshift Serverless with Amazon MWAA
AWS Big Data
APRIL 25, 2024
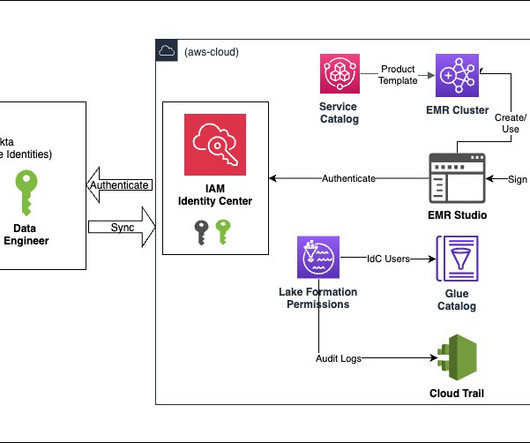
The policies attached to the Amazon MWAA role have full access and must only be used for testing purposes in a secure test environment. For more information, see Accessing an Amazon MWAA environment. For production deployments, follow the least privilege principle.











































Let's personalize your content