

How Cargotec uses metadata replication to enable cross-account data sharing
AWS Big Data
JUNE 7, 2023
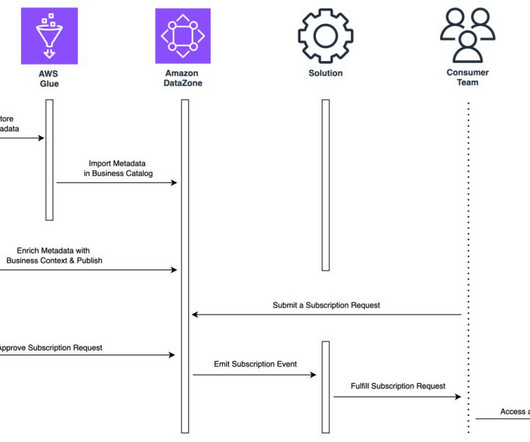
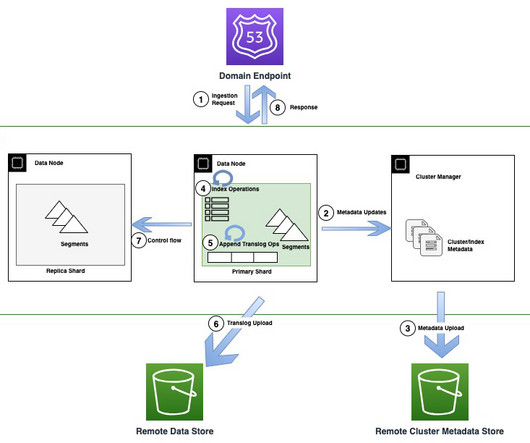
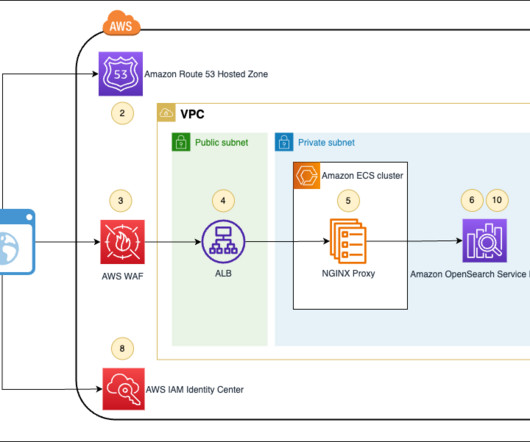
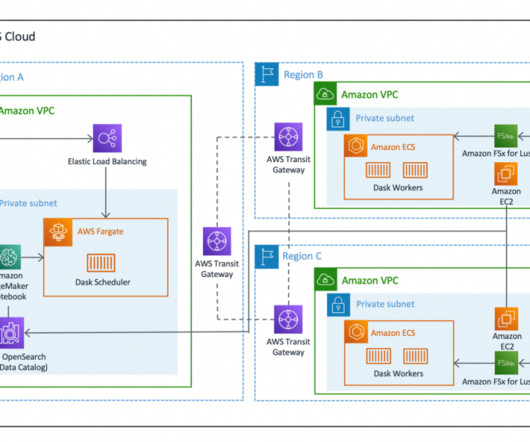
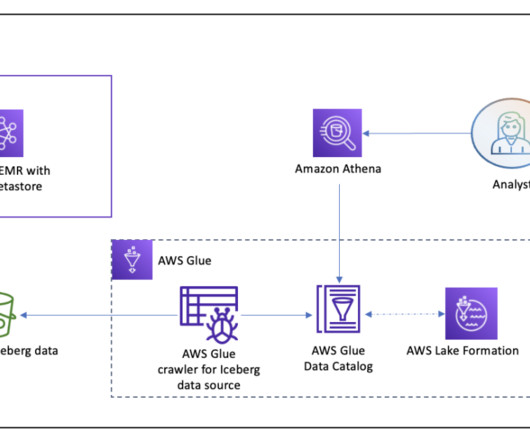
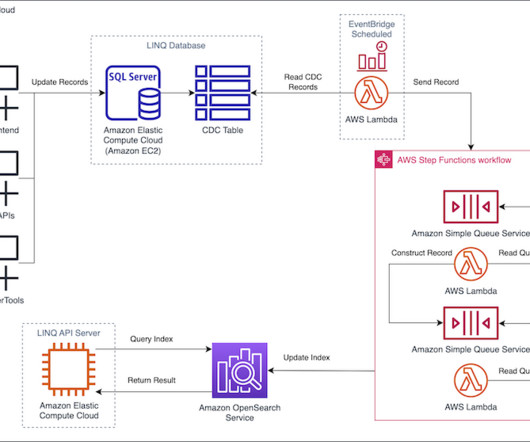
They chose AWS Glue as their preferred data integration tool due to its serverless nature, low maintenance, ability to control compute resources in advance, and scale when needed. To share the datasets, they needed a way to share access to the data and access to catalog metadata in the form of tables and views.










































Let's personalize your content