

Multicloud data lake analytics with Amazon Athena
AWS Big Data
MARCH 18, 2024
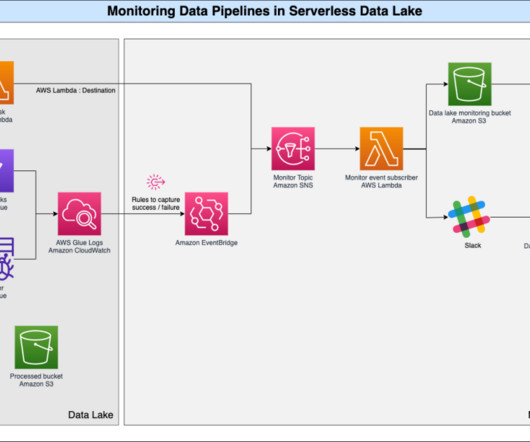
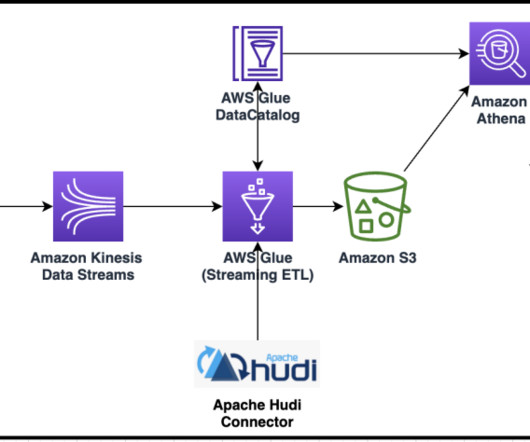
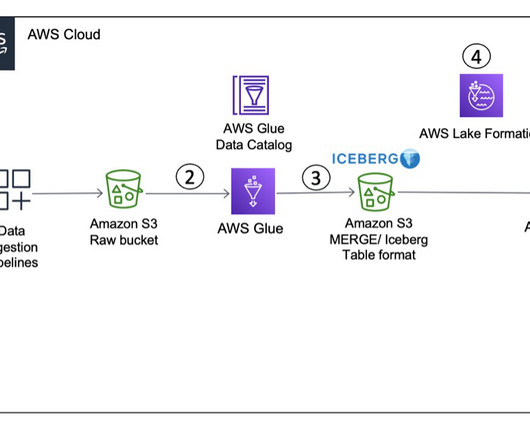
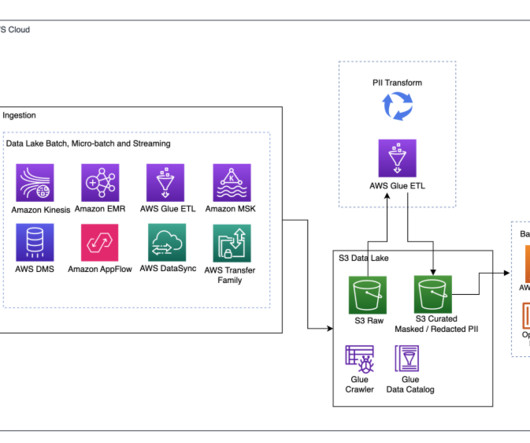
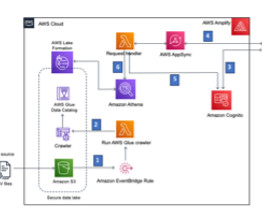
Many organizations operate data lakes spanning multiple cloud data stores. In these cases, you may want an integrated query layer to seamlessly run analytical queries across these diverse cloud stores and streamline your data analytics processes. This serves as the S3 data lake data for this post.










































Let's personalize your content