


HDFS Data Encryption at Rest on Cloudera Data Platform
Cloudera
APRIL 23, 2021
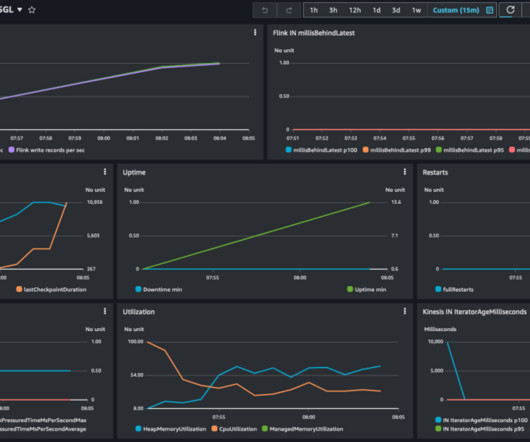
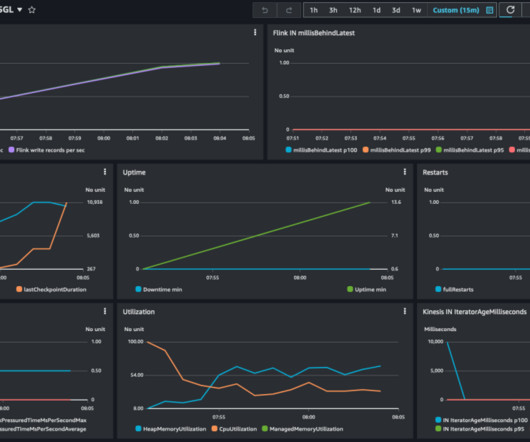
Each HDFS file is encrypted using an encryption key. To prevent the management of these keys (which can run in the millions) from becoming a performance bottleneck, the encryption key itself is stored in the file metadata. For every file created or copied into HDFS encryption zone, a data encryption key (DEK) is created .















































Let's personalize your content