

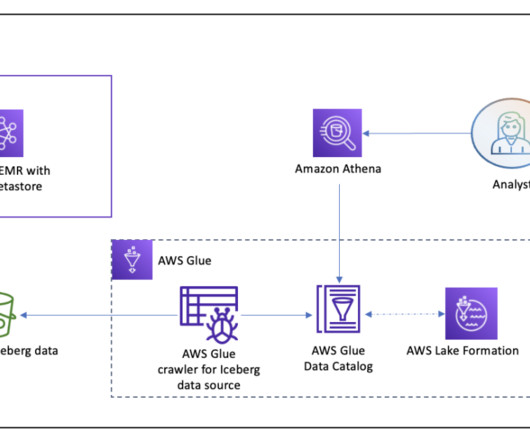
Design a data mesh pattern for Amazon EMR-based data lakes using AWS Lake Formation with Hive metastore federation
AWS Big Data
JUNE 10, 2024
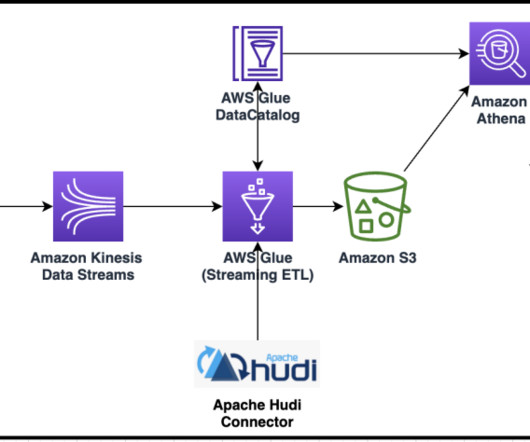
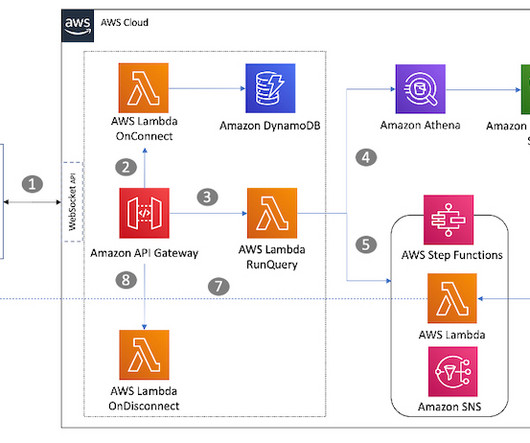
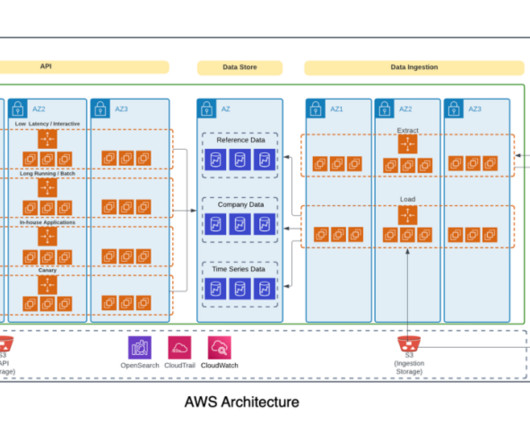
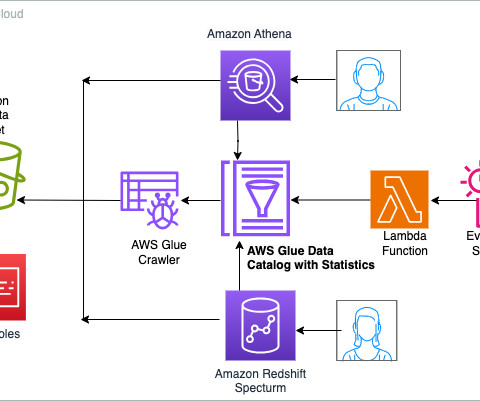
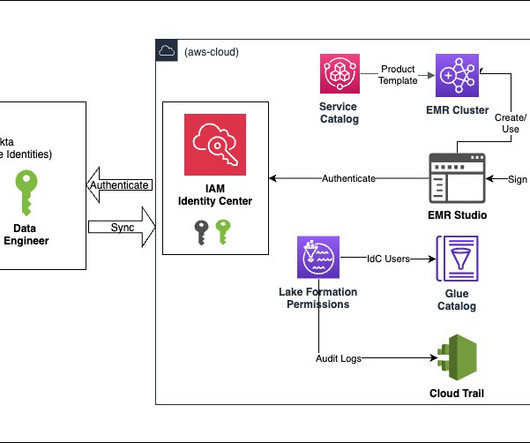
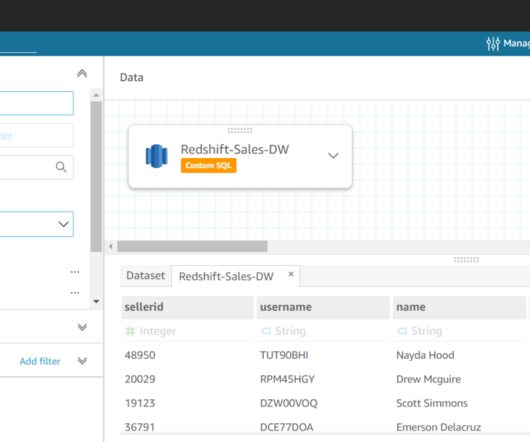
For detailed information on managing your Apache Hive metastore using Lake Formation permissions, refer to Query your Apache Hive metastore with AWS Lake Formation permissions. In this post, we present a methodology for deploying a data mesh consisting of multiple Hive data warehouses across EMR clusters.










































Let's personalize your content