


No Training Data? No Problem!
Dataiku
MARCH 31, 2023
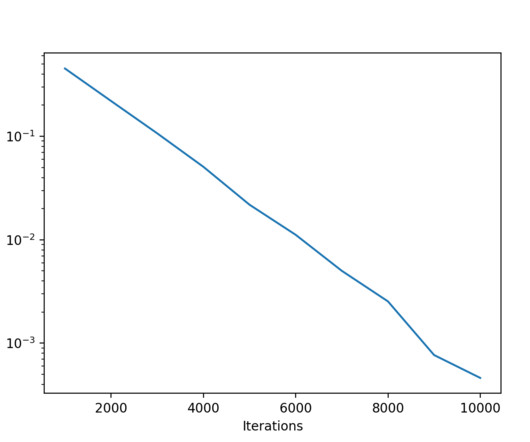
A significant quantity of training data has long been a key requirement of successful machine learning (ML) projects. In this blog post, we will see that new state-of-the-art approaches make it possible to mitigate or overcome this constraint in the context of computer vision.














































Let's personalize your content