

Enhance monitoring and debugging for AWS Glue jobs using new job observability metrics, Part 3: Visualization and trend analysis using Amazon QuickSight
AWS Big Data
MARCH 29, 2024
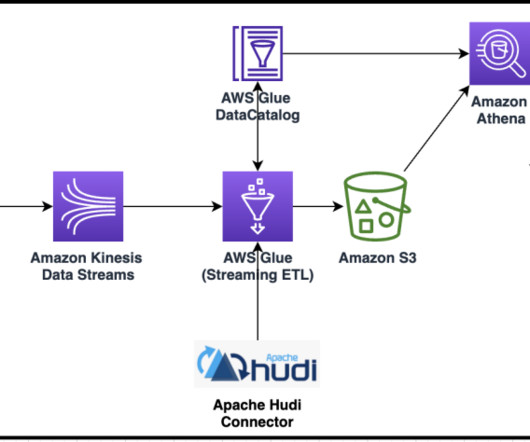
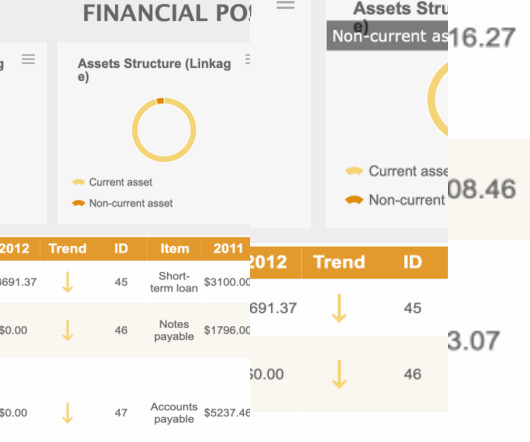
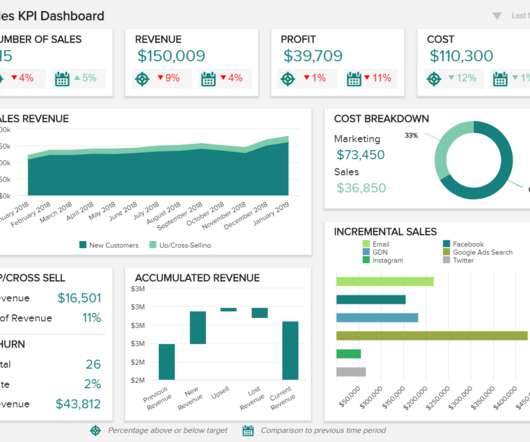
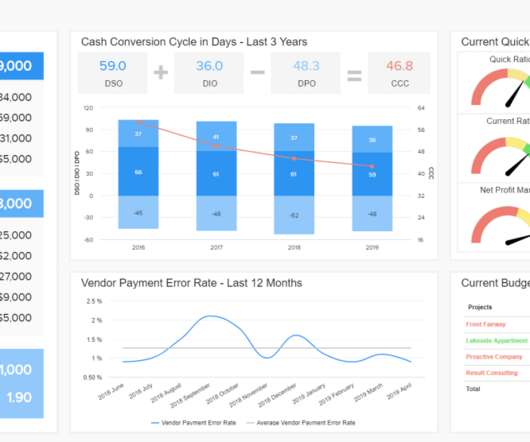
QuickSight makes it straightforward for business users to visualize data in interactive dashboards and reports. You can slice data by different dimensions like job name, see anomalies, and share reports securely across your organization. Typically, you have multiple accounts to manage and run resources for your data pipeline.





































Let's personalize your content