

GraphDB in Action: Smells Like Semantics Spirit
Ontotext
DECEMBER 20, 2023
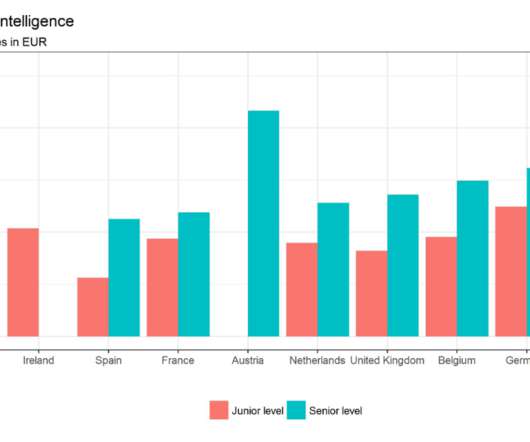
Take Google’s knowledge graph, underpinning Google’s search, we can use it to ask when a historical figure was born, which cities hosted the Olympics, how to get to the nearest pizza, and so on. The answer is through the wealth of object, text and image data, which serve as a reference to olfactory experiences. van Erp, M.,





































Let's personalize your content